《A Novel Table-to-Graph Generation Approach for Document-Level Joint Entity and Relation Extraction》阅读笔记
文档级关系抽取(DocRE)的目的是从文档中提取实体之间的关系,这对于知识图谱构建等应用非常重要。然而,现有的方法通常需要预先识别出文档中的实体及其提及,这与实际应用场景不一致。为了解决这个问题,本文提出了一种新颖的表格到图生成模型(TAG),它能够在文档级别上同时抽取实体和关系。TAG的核心思想是在提及之间构建一个潜在的图,其中不同类型的边反映了不同的任务信息,然后利用关系图卷积网络(RGCN)对图进行信息传播。此外,为了减少错误传播的影响,本文在解码阶段采用了层次聚类算法,将任务信息从提及层反向传递到实体层。在DocRED数据集上的实验结果表明,TAG显著优于以前的方法,达到了当前的最佳性能。
1 Introduction
关系抽取(RE):从自然语言文本中抽取实体之间的语义关系,并将其表示为结构化的三元组。
句子级RE:在单个句子的范围内,抽取句子中实体对之间的关系。
DocRE:在多个句子的范围内,利用跨句子的语义推理,抽取文档中实体对之间的关系。
大部分现有的DocRE方法只关注抽取关系,这些方法假设实体及其对应的提及已经预先给定。
流水线方法
流水线框架是一种用于DocRE的方法,该框架首先将整个任务划分为提及抽取(ME)、共指消解(COREF)和实体关系抽取(RE)三个子任务,然后使用单独的模型逐步进行每个任务(Zaporojets等人, 2021)。然而,该框架的缺点在于它忽略了子任务之间的潜在依赖性,影响了模型的性能。
早期的联合考虑子任务的方法
一些早期的联合考虑子任务的方法,如(Eberts等人, 2021; Xu等人,2022)仍然将COREF和RE任务分别建模,导致在编码和解码阶段可能产生的偏差。一方面,这类方法仍然存在信息共享不足的问题。它们要么完全依赖于共享的语言模型(如BERT)(Eberts等人,2021),要么只考虑从RE到COREF的单向信息流,忽略了其他跨任务的依赖性(Xu等人, 2022)。另一方面,这类方法大多采用流水线风格的解码,即先识别提及范围并形成实体簇,然后对每对实体进行关系分类。流水线风格的解码不仅耗时,而且面临着错误传播的问题。实体提及抽取的结果可能影响关系抽取的性能,并导致级联错误。Xu等人(2022)引入一个正则化项来缓解这个问题,但是问题仍然没有完全解决。
本文提出了TAG,将COREF和RE两个任务融合为一个表格填充任务的方法,使用一个表格填充器对原始文本进行编码,并在粗粒度上生成提及和关系的候选集合。为了表示共指和关系的信息,本文动态地构建了两个图结构,其中节点是提及,边的权重由表格填充器的置信度得分决定。此外,本文还在提及层面上建立了一个句法图,以缓解长距离依赖问题,并显式地引入句法信息。本文将这三个图视为三种不同类型的边,并利用关系图卷积网络(RGCN)来在细粒度上捕捉任务之间的隐含依赖关系。本文的粗到细的方法利用了丰富的节点表示,通过语义和句法链接传递信息,这与之前仅从语言模型中共享范围表示的多任务系统不同。本文还采用了一个直观的假设,即同一实体簇中的提及应该与其他实体形成相似的关系链接,并将层次聚类算法(HAC)应用到提及聚类中,以利用关系信息来提升共指消解的性能,从而避免错误传播的风险。本文在广泛使用的DocRE基准数据集DocRED上进行了实验,结果表明,本文提出的TAG模型显著优于现有的方法,并达到了新的最佳水平。本文还在DocRED的一个修订版本Re-DocRED上报告了联合实体和关系抽取的第一个结果,为未来的研究提供了一个新的基准。
2 Problem Formulation
DocRE的任务是,给定一个包含L个单词的文档D,端到端地同时提取所有实体和关系。因为某个实体可能在文档中以不同的形式多次出现,所以提取过程涉及到以下三个子任务:
-
提及抽取(ME):从原始文档中抽取所有可能的实体范围
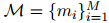
-
共指消解(COREF):是将文档中的局部提及分组为实体簇



-
关系抽取(RE):在预定义的关系集合



与以前的工作不同,本文将COREF和RE两个任务用表格填充框架来建模,即对每对提及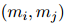






3 Methodology

3.1 Mention Extractor
考虑到DocRE任务中重叠提及的情况较少,本文为了提高效率,采用了一种序列标注(sequence-based)的方式来抽取提及。该方法使用BIO标签来标记提及的开始、内部和结束位置,相比于基于跨度的方法,虽然牺牲了一些表达能力,但是降低了时间复杂度,只需要线性时间就可以完成。本文借鉴了Devlin等人(2019)的工作,先用预训练语言模型(PLM)对文档中的词进行向量化,然后用一个分类器对每个词进行BIO标签的分配,用
3.2 Table-to-Graph Generation
3.2.1 Biaffine Table Filler
给定一个文档




式中,A为最后一层Transformer的多头注意矩阵。


式中,



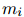

定义


式中,
采用双仿射注意力机制将提及特征转换为表示共指消解或关系链接的标量分数表


式中,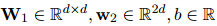






3.2.2 Latent Graph Construction
Coreference and Relational Graphs.
在得到共指消解和关系分数

本文将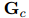



Syntactic Graph.
现有的提及图模型往往忽略了句法信息,导致模型难以捕捉长期依赖关系。为了解决这个问题,本文构建了语法图,在提及图中明确地引入句法信息,使模型能够在精细的级别上学习长期依赖关系。为了构建语法图,需要考虑两个方面:一是如何将句法信息转换为图结构,二是如何在图结构上进行信息传播。本文考虑了几种可选的方法来实现这两个方面。例如,一种直观的解决方案是将单词的依赖树转移到图中,其中提及是节点,依赖关系是边。这种方法可以保留句子内部的句法结构,但是无法捕捉句子之间的句法关系。本文参考了以前的作品(Christopoulou等人, 2019;Zeng等人, 2020),并采用了一种基于共现的方法,即使用双向边将同一句子中的所有提及连接起来,从而增强句子内部的语义关联。
3.2.3 Propagating Information with R-GCN
COREF和RE是两个重要的信息抽取任务,它们可以从文本中识别实体和实体之间的关系。然而,现有的方法往往分别处理这两个任务,忽略了它们之间的交互和语法信息的作用。为了解决这个问题,本文提出了一个信息传播模块,它可以考虑COREF和RE任务之间的交互,并结合显式语法信息,从而改进提及表示。具体来说,本文提出了一种基于潜在图的方法,它可以将提及图上的三种不同类型的边(分别对应COREF、RE和语法)进行统一建模。本文的模型可以利用不同类型的边来聚合邻居特征,从而增强提及的语义和结构信息。为了在提及图上应用关系图卷积网络,本文设计了一个更新过程,它可以根据边的类型和权值来调整不同邻居的贡献。本文的模型可以初始化节点嵌入为提及的隐藏特征,然后通过多层的信息传播来更新提及表示。与以前的方法不同,本文的模块可以并行集成跨任务信息,并提取两个任务的相关提及特征,从而实现更有效的信息抽取。

3.2.4 Classifier
经过N次传播后,本文使用优化后的提及嵌入




式中,

式中,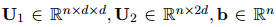




3.3 Training
Table Encoder.
给定提及对






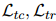
Coreference Resolution.
细粒度共指消解(fine-level coreference resolution)的训练目标和标签与表格编码器(table encoder)中的共指链接预测(coreference link prediction)是一致的。唯一的区别是它使用优化后的提及表示(refined mention representations)作为输入。用
Relation Extraction.
对于提及对





对所有提及对进行求和,计算细级关系提取损失
最后,对TAG进行联合优化

其中
3.4 Decoding
为了避免管道解码固有的错误传播问题,本文设计了一种解码算法,使上游任务(COREF)能够有效地利用下游任务信息(RE)。
Entity Cluster Decoding.

本文根据算法1中描述的层次聚类算法(HAC)来解码实体簇。HAC的核心是计算两个簇





在训练阶段,如果


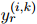





使用每个簇中的提及对之间的平均汉明距离作为
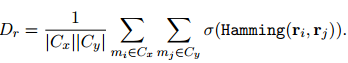
4 Experiments
4.1 Setup
Dataset.
-
DocRED
-
Re-DocRED ( 在Re-DocRED上报告了第一个联合提取结果)
Metrics.
......
4.2 Overall Performance


本文对TAG与其他一些用于联合实体和关系抽取的基线方法进行了比较。早期的方法使用LSTM作为上下文编码器。在此基础上,Verlinden等人(2021)提出了KB-IE。该方法将知识库(维基百科和维基数据)的背景信息集成到联合IE模型中。最近的方法通常对PLM进行微调,以学习更丰富的特征。Xu等人(2022)实现了标准的流水线方法,以及具有共享编码器和联合损失的联合方法。他们还提出了JointM+GPGC,实现了从RE到COREF的单向信息流。Eberts等人(2021)提出了JEREX,结合了多实例学习,提高了RE的性能。Giorgi等人(2022)开发了一种带有复制机制的序列到序列模型,seq2rel,性能较差,但效率更高。此外,本文还设计了一个强大的基线方法,TableFiller。它消除了图形模块,采用了简单的启发式解码算法。它只包含一个提及提取器,一个双仿射编码器和一个分类器。
表1比较了TAG与其他基线方法在DocRED上的整体性能。可以观察到,






表2显示了TABLEFILLER和TAG在Re-DocRED上的性能。与DocRED相比,它们在共指消解方面表现相似,但在关系抽取方面有很大的提升。这与之前的发现(Tan等人,2022)一致。关于架构上的差异,TAG在开发集和测试集上的所有子任务中都一致优于TABLEFILLER,突出了TAG对于文档级联合抽取的有效性。
4.3 Analysis on Reasoning Skills

文档级关系抽取需要具备丰富的推理能力,包括常识推理和逻辑推理(Yao et al., 2019)。证据句子的数量是区分不同推理类型的一个重要指标。为了展示TAG方法的优势,本文将根据证据句子的数量,将关系召回率可视化在图3中。对于没有证据句子的关系实例,只能依靠预训练语言模型的知识或训练语料库中的信息来推断。TAG方法在这种情况下比TABLEFILLER方法提高了1.8%的召回率,它们使用的是相同的编码器,这说明了TAG方法具有更强的常识推理能力。此外,TAG方法也在需要2-4个证据句子的关系上持续领先于TABLEFILLER方法,这些关系涉及到共指实体指称的区分或桥接实体的逻辑推理。这反映了图模块和解码算法对共指推理和多跳逻辑推理的有效性。最后,TAG方法在需要5个或更多证据句子的关系上显著提升了召回率(5个句子为6.0%,6个以上句子为8.3%),表现出了TAG方法在复杂逻辑推理上的优势。
4.4 The Impact of Graph Propagation

图4显示了不同类型的边对关系抽取F1分数的影响,其中-Coref、-Rel和-Syntax分别表示去除共指、关系和句法边。从图中可以看出,所有模型的F1分数在2/3层图时达到最高,然后迅速下降。本文认为,层数越深,有利于信息在更大范围内传播,但是梯度消失问题会削弱这一优势。此外,所有消融模型的表现都不如TAG全通道模型,说明各种类型的边都对提高推理能力有正面作用。层数和边的类型对RE F1有重要影响,而对共指消解的影响则相对较小。
4.5 Effectiveness of Decoding

本文提出了一种实体聚类解码算法,以提高共指消解的性能。表3展示了在不同的平衡超参数ρ下,该算法与MUC、B3和CEAFϕ4的平均F1分数和硬实体级F1分数的对比。结果表明,当ρ = 0.1时,该算法达到了最优的表现,两个指标的F1分数均比原来提高了0.3%。虽然引入关系距离Dr使得HAC解码算法的性能有所提升,但并没有达到预期的效果。同时,调整ρ的值对结果的影响也不大。这些发现说明,共指消解对于不同的设置具有较强的鲁棒性。为了探究这种现象的原因,本文对银标COREF标签和预测分数之间的相关性进行了分析,结果如表4所示。可以看出,关系惩罚和银标标签之间的相关性为-0.72,显著低于共指分数和银标标签之间的相关性。这种强烈的关联部分解释了前面的结果。它也表明,Dr只是一个较弱的优化信号,而过高的ρ值可能会降低COREF的性能。
5 Related Works
......
6 Conclusion
本文提出了一种名为TAG的表格到图生成模型,它能够从文档中同时抽取出实体和关系。与传统方法不同,本文采用了一个表格填充的框架,将共指消解和关系抽取两个任务融合在一起,并通过粗到细的策略实现了这两个子任务之间的信息共享。为了避免错误传播的问题,本文在解码阶段对HAC算法进行了改进,利用关系抽取的预测结果来提升共指消解的效果。在广泛使用的DocRED数据集上的实验表明,TAG模型显著优于现有的方法。进一步的分析也验证了本文模型中各个模块的有效性。
热门相关:凤逆天下:战神杀手妃 我寄人间 魔葫 我有一个进化点 美食供应商