支撑百万商户、千亿级调用:微盟如何通过链路设计降本40%? 一分钟精华速览
一分钟精华速览
在典型的分布式系统中,用户的一个请求到达组合的前端服务后,前端服务会分发请求到内部的各个服务,每次调用都涉及跨系统的一次请求和一次响应。在有大规模、高并发请求量的系统中,如何标识这些请求及存储这些调用信息,并形成调用链?如果系统的某两个服务间出了问题,又如何为业务方提供可视化的展现形式以快速排障?
本文总结了微盟支持千亿级规模的调用链实践,详解平台的建设目标、设计思路和落地效果。

作者介绍

微盟APM团队负责人——向明亨
TakinTalks稳定性社区专家团成员。2017年加入微盟,目前负责公司APM体系建设,包含APM体系从规范到实施,推动APM体系在公司的落地,主导了微盟APM平台、监控告警平台等平台的建设。
温馨提醒:本文约5000字,预计花费10分钟阅读。
后台回复 “交流” 进入读者交流群;回复“0411”获取课件资料;
背景
作为SaaS领域唯二在港交所上市的企业之一,微盟累计服务了300万+入驻商家,并基于腾讯社交网络为众多商家提供SaaS和营销服务。微盟业务的复杂性,体现在其技术团队不仅需要满足内部能力建设需求,也需兼顾营销云上大量外部租户的使用需求。
在流量生态方面,微盟集团SaaS产品拓展了多个流量平台,如QQ小程序、QQ浏览器、抖音小店等,随着业务端的渠道复杂化和流量的日益增长,业务方的观测和排障需求也产生了变化。
一、微盟为什么自主设计调用链体系?
1.1 多集群排障,依赖调用链工具
在单应用场景下,大家通常通过监控或者日志来排障,但在集群状态下它就会出现问题。比如一个下单流程,同时涉及了 A/B/C/D/E 服务,此时需先确定故障出现在哪个应用,而依赖传统的日志或者监控,无法做到快速定位故障。
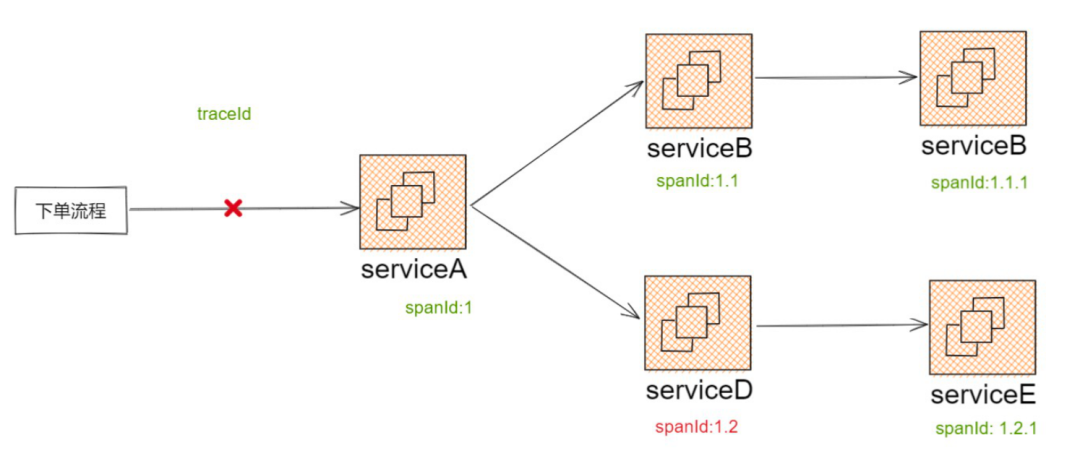
利用调用链工具,则可以串起请求的全过程,在链路中能直观看到是哪个服务出现了问题,帮助快速定位故障,它是多集群状态下排障的最佳解决方案。
1.2 链路开源组件多,但无法满足需求
1.2.1 开源调用链工具
业界常用的链路开源工具有Skywalking 、ZipKin、 Jaeger 等等,我们根据微盟需求做了以下比对和分析。

1.2.2 为何不选用开源链路系统
市面上有如此多开源工具,微盟为何还要做自己的调用链体系?
从整体设计要求考虑——
主Java:微盟大部分应用都是Java;
多语言:除Java外,还有Go、Node.js、Python等语言;
海量数据:要求监控数据尽可能多,因此数据规模较大;
业务复杂:既有 SaaS 也有PaaS,业务背景相对比较复杂。

从技术选型角度分析——
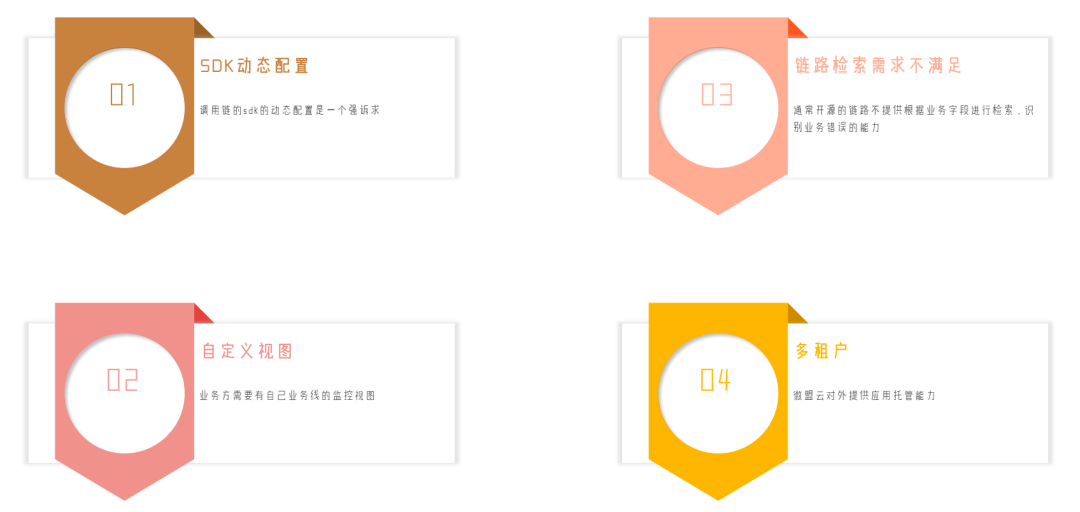
SDK动态配置:调用链的SDK动态配置是一个强诉求,而开源的调用链工具不支持自定义配置。比如,需要设置拦截哪些组件、哪些组件不收集调用链等,开源工具无法实现;
自定义视图:业务方需要有自己业务线的监控视图。微盟业务线众多,业务方会有基于团队和业务线的监控诉求,而开源工具无法满足该类诉求;
链路检索需求不满足:通常开源的链路不提供根据业务字段进行检索,识别业务错误的能力。需要在不侵入业务方业务流程的前提下,满足业务方的更高阶要求;
多租户:微盟云对外提供应用托管能力。除满足对内需求外,也对在微盟云平台部署应用的租户提供调用链服务。
二、微盟调用链体系做了哪些设计?
2.1 新调用链架构设计
我将从三个部分来讲述新的调用链设计——数据收集、数据传输协议、数据应用。
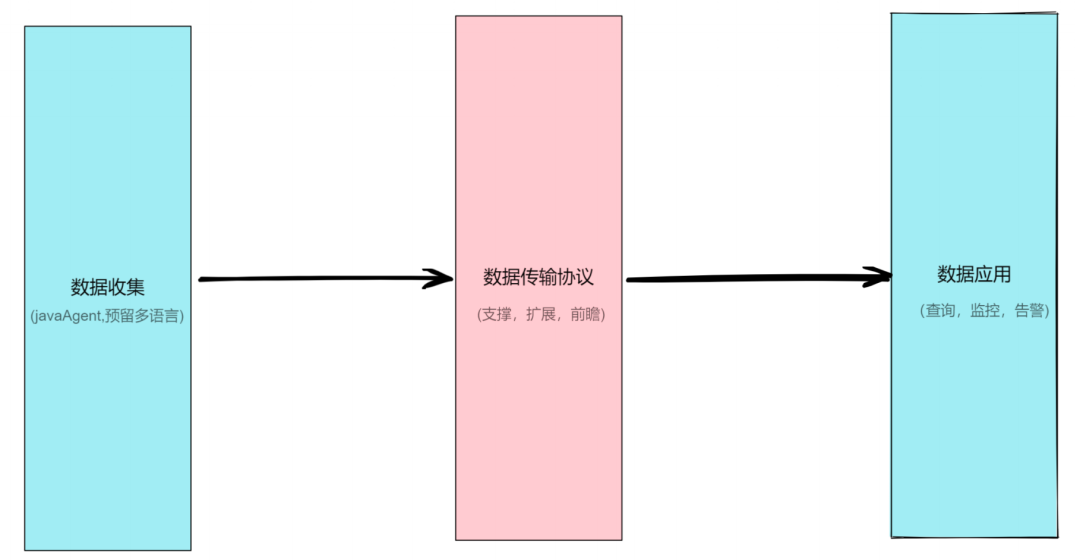
数据收集:采用 JavaAgent 来提供无侵入的支持,同时我们也在设计阶段预留了多语言的支持。
数据传输协议:数据传输协议相对来说没那么好改,它需要具有前瞻性、支撑性和扩展性,在协议设计时需更慎重。
数据应用:支撑丰富的检索、监控、告警的诉求。
基于以上三点考虑,我们设计了微盟调用链体系,其整体架构如图所示。
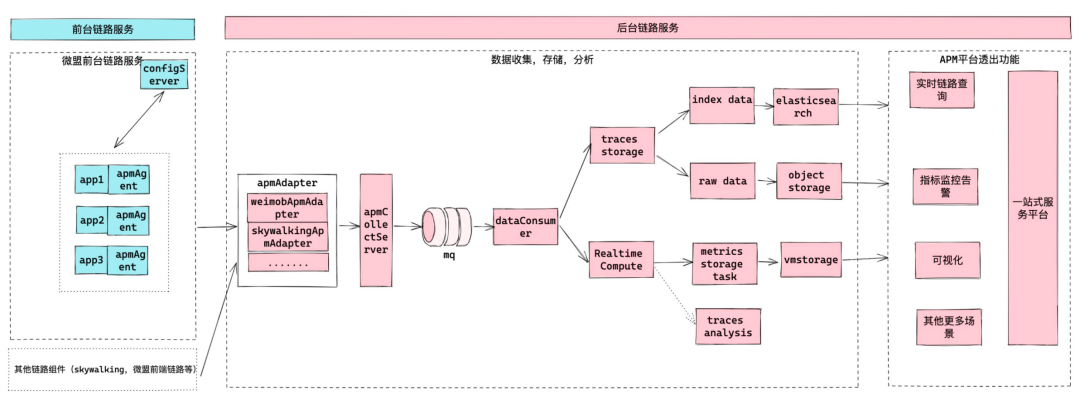
(微盟调用链体系架构图)
2.2 前台链路服务
前台链路服务的建设,我们需要达到的三个目标:
- 降低接入成本;
- 支持动态化配置;
- 支持多语言。
2.2.1 降低接入成本-JavaAgent
从节省成本的角度,我们选择了无侵入的JavaAgent技术,而非使用SDK构建。
这里简单先介绍JavaAgent的技术实现过程——在启动JVM时注入一个插件,这个插件相当于一个“外挂”,我们在插件里对业务的一系列关键流程注入了观察埋点。
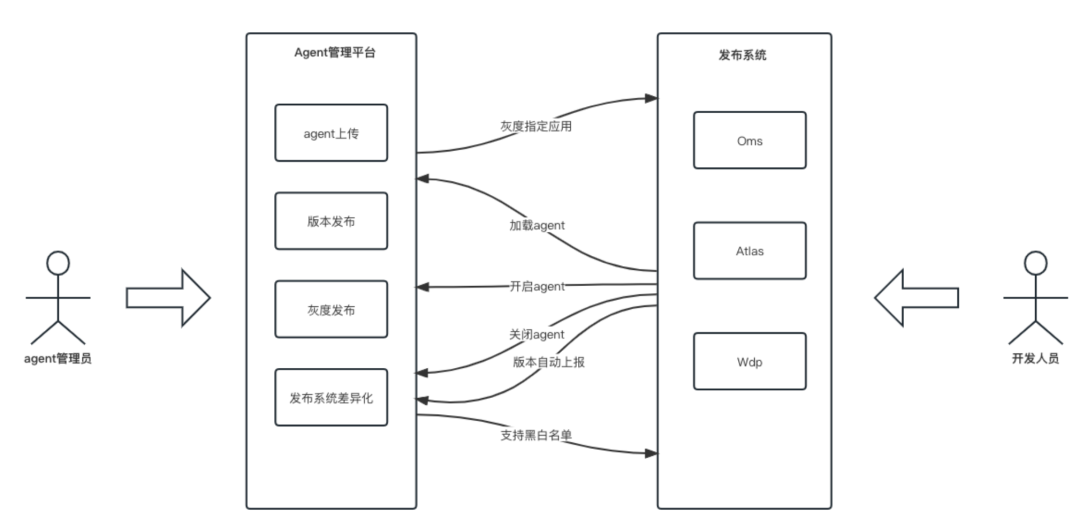
我们基于JavaAgent技术搭建了Agent管理平台,实现Agent的上传、版本发布、灰度、发布系统差异化等的一站式管理,同时由于微盟的主要语言是Java,所以大部分接入成本是非常低的。从业务方使用的角度,只需要在后台通过开关操作,打开调用链并进行项目重启后,即可自动显示应用,并快速观测其链路情况。
为何不选择常规的SDK构建?因为业务方需要引入SDK并进行相关代码注入和配置,随着微盟业务的扩张,后续如果需要支撑更多组件,当系统需要升级或SDK出问题时,推动业务方升级的成本则会非常高。
因此最终我们推荐采用JavaAgent技术来实现,其在减少业务方接入成本、提高整体收益、多方协作满意度等方面表现都相对出色。
2.2.2 动态化配置
1)实现原理-借助apollo配置中心
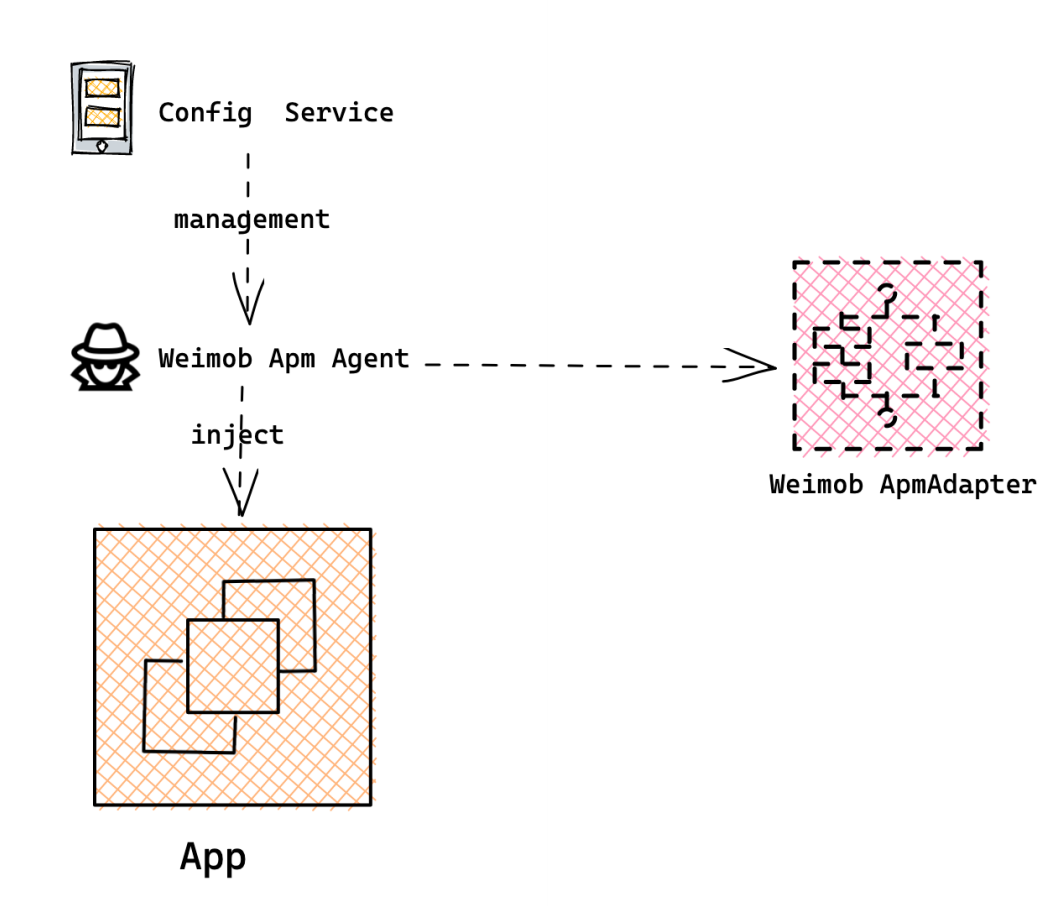
我们借助了开源的apollo(阿波罗)配置中心来支持动态化配置,其实现过程如图。服务会动态地、实时地下发配置,Agent 接收到配置后进行相应的行为验证。
2)踩坑分享-Agent 类加载问题
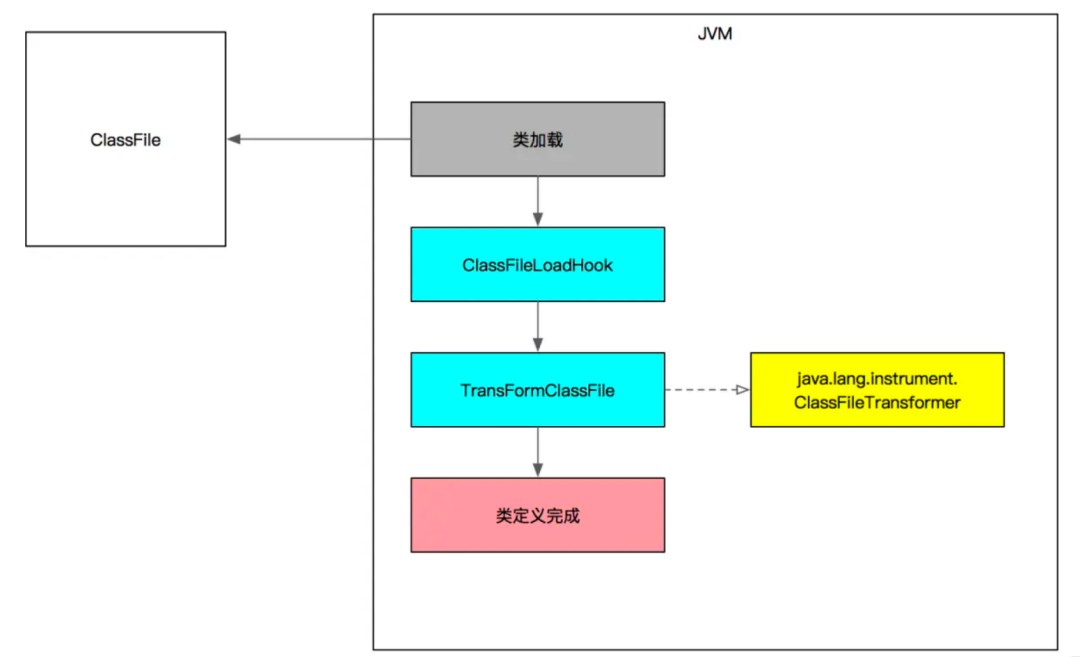
在Agent接入时,也会碰到一些问题,其中踩过的最大的坑就是类加载问题。
在Agent中使用到的类和jar包和业务方使用的类产生了冲突,比如Agent 使用了一个低版本、业务方使用了高版本的类,此时既有可能加载高版本,也有可能加载低版本,就产生了版本冲突进而导致业务方系统故障。
我们的解决办法是Agent利用Shade工具进行依赖包重命名,这样类加载时就不再互相干扰。这个踩坑经验希望能对其他实践者产生帮助,避免重走弯路。
2.2.3 多语言支持
微盟老的调用链体系是基于自制的上下文实现的,支持 Trace ID 、 RPC ID 等等,那么如何进一步提供多语言支持,尽可能地减少基础架构的维护成本?
我们选择借助开源的力量,除支持微盟协议外,平台还支持了Skywalking的跨进程传播的协议,借助Skywalking丰富的SDK,既能满足的业务方更小众的语言的监控诉求,也能同时减少维护成本。
2.3 调用链数据结构
调链数据结构上我们想达成的三个目标——支撑性、扩展性、前瞻性。

我们借鉴了OpenTelemetry标准和Skywalking的协议,构建了微盟自己的链路数据结构,如下图所示。
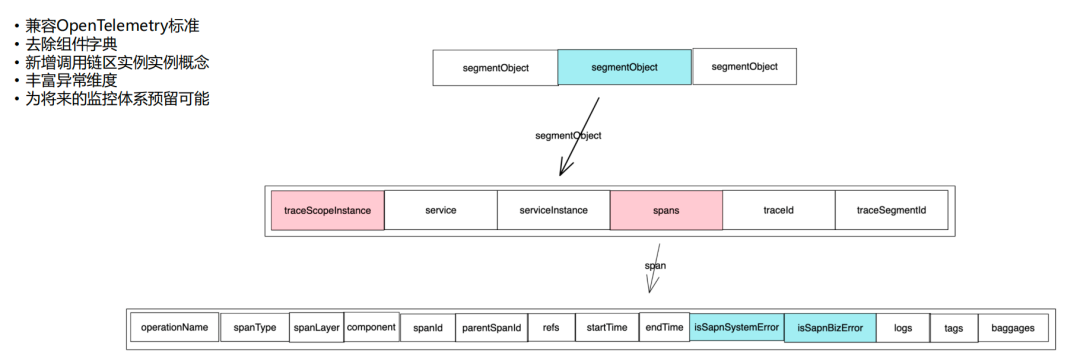
2.4 后台链路服务
后台链路服务我们需要达到以下四个目标:
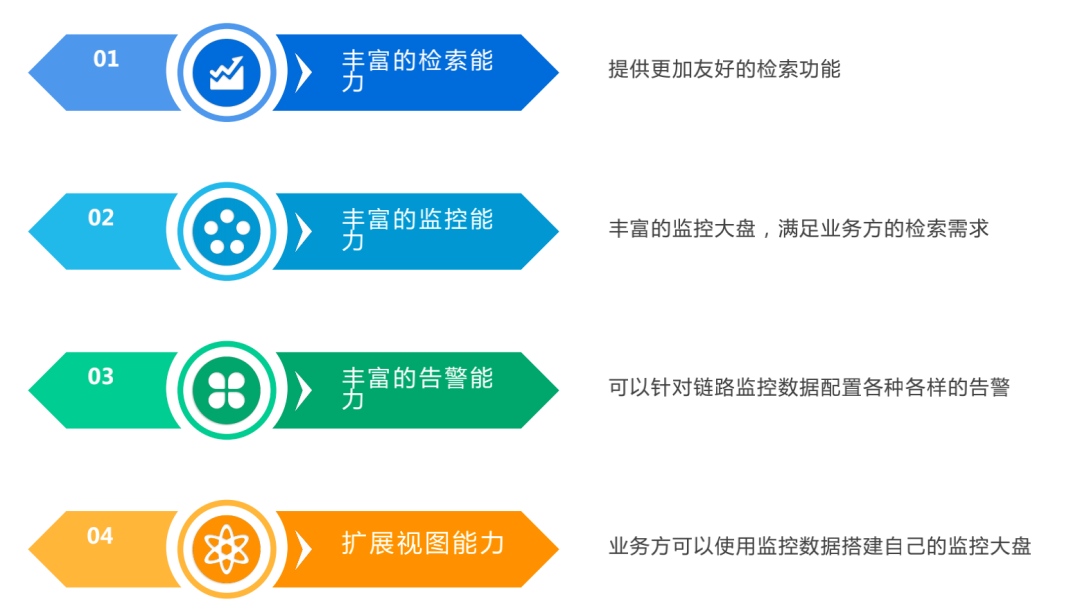
那么如何才能做到?首先是上面提到的数据结构扩展。然后构建了高性能的监控体系,把数据存储到VictoriaMetrics(时序数据库),做更多可视化展示。最后是支撑业务异常的检索和关键业务的检索,以满足业务方多样性的检索、监控、可视化诉求。
三、调用链体系在微盟的落地效果如何?
该部分我将结合微盟的实际落地效果,展开讲解上一章末的目标是如何达成的。
3.1 业务关键字能力
基于对微盟业务的思考,我们做了业务关键字的能力,这里不在于技术的实现,而在于这个诉求本身如何满足。
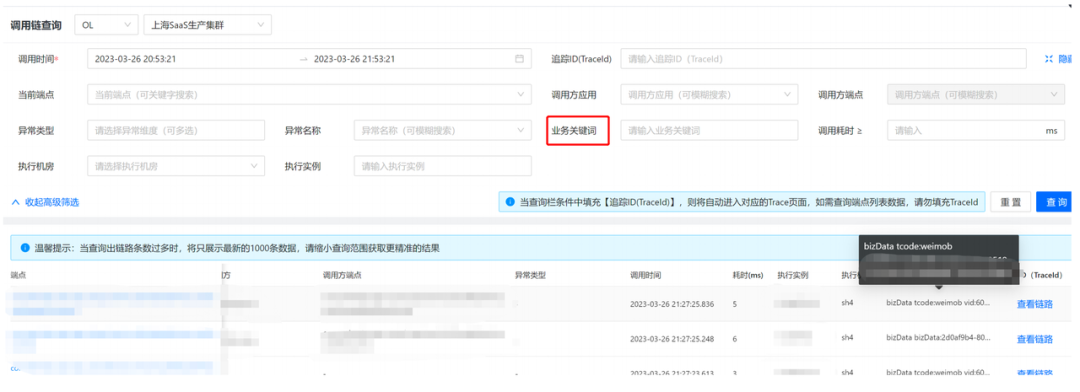
传统的调用链体系通常会支持 Tag 类检索,但是 Tag 检索需要业务方做手动埋点,才能进行后续的检索。除了业务方的人力投入问题,这类检索常常不能完全满足业务方检索需求。而业务关键字能力则能以最小的人力、存储成本,达成更好的效果。
以微盟的典型场景为例,某用户下单出现问题,找到业务部门投诉,传统的调用链此时是无法确定用户链路的。而通过提取入参的关键业务参数,把它分析到业务关键字里去,此时只需要输入该用户的ID,在平台进行检索即可完成此项诉求。平台会默认收集入参中的脱敏关键参数,其他无关信息则不做保留,以此减轻ES存储成本,用约10%的成本来完成100%的观测诉求。
3.2 业务异常能力
收集业务场景的所有Dobbo接口的出参信息并做序列化,业务方则可以通过异常码来识别异常。

假设业务上有下单流程失败了,此时会抛出一个异常码,此时调用链上可以一目了然,并能下钻到详细信息。
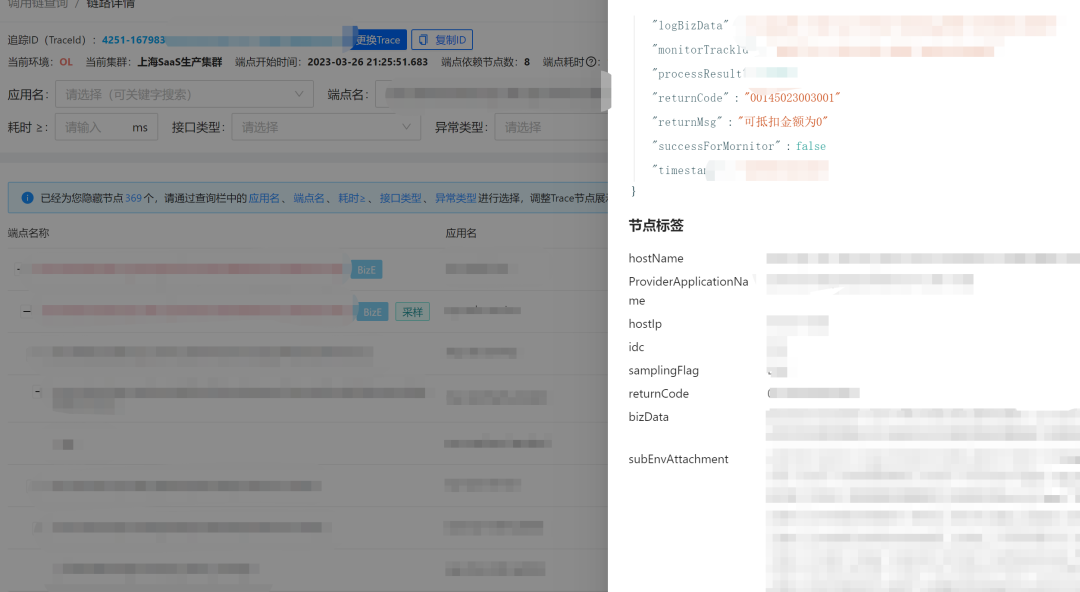
业务异常梳理后不仅可以做展示,也可以做监控大盘,看到业务异常的整体概况。

如果业务方有监控告警的诉求,也可以在平台上设置想要监控的异常,并选择业务异常码进行监控。
3.3 指标能力
把指标存储到了时序数据库,它支持Prometheus 标准的查询。在此基础上,业务方可以各自进行大盘构建。
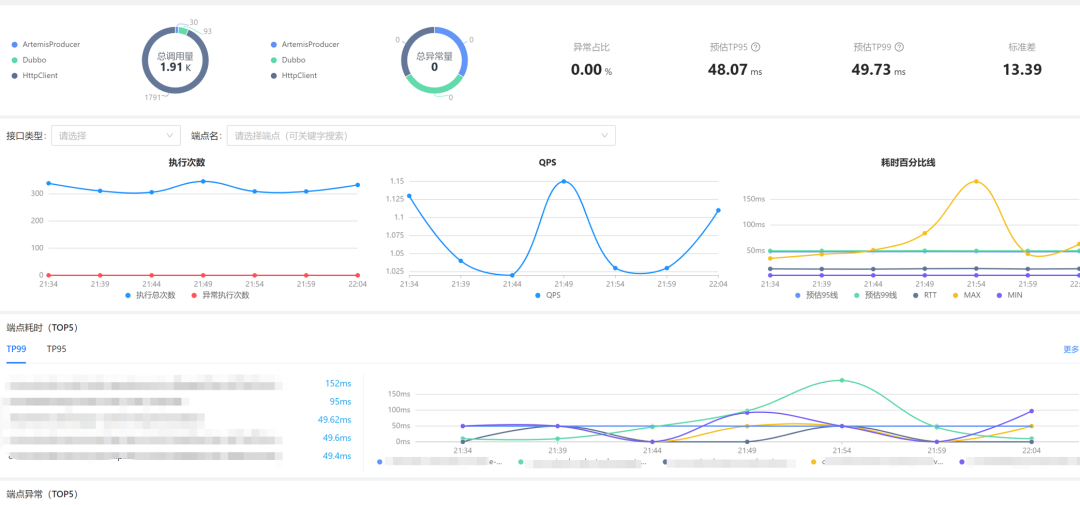
在大盘上可以看到总调用量、总异常量、异常占比、TP线等等。如业务方需要了解某接口的场景,也可输入进行检索。端点耗时、端点异常等排行,基于业务侧应用维度的概况在平台上一目了然。
平台也和灰度做了打通,在调用链体系,也能深入识别到灰度环境下的链路概况。

3.4 端点分析
3.4.1 当前端点分析
端点分析中可以进行趋势分析,查看高耗时链路,查看异常链路,点击异常链路可以进入异常链路页面,查看异常链路详细情况。整个查询体系、监控体系、告警体系、日志体系都互相联动。
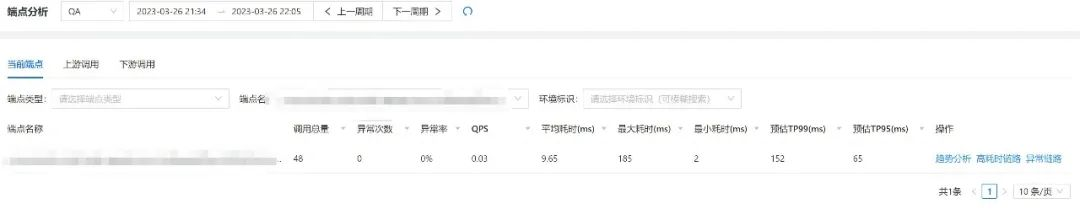
(微盟调用链-端点级别的展示查询)
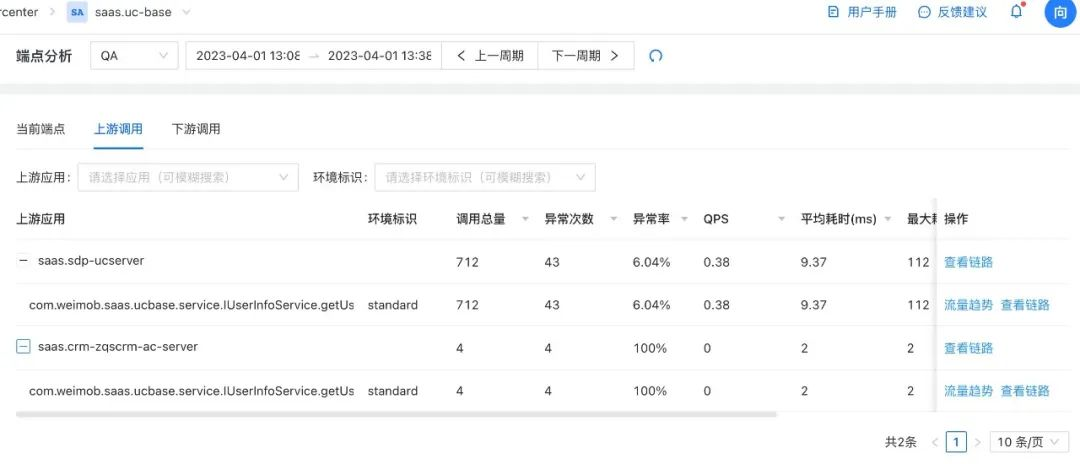
3.4.2 上下游分析
业务方有个比较普遍的诉求,是能看到应用的上下游调用情况,而不仅仅只是当前应用的概况。因此,我们基于调用链的数据采集功能,收集上下游调用的应用服务名称、服务实例以及其他信息,再进一步分析出上下游的链路调用情况,比如调用总量、异常次数、异常率、平均耗时等等。
3.5 APM一体化
3.5.1 观测能力
APM一体化不仅为链路提供了更丰富的能力,还和指标体系、日志体系打通,实现了体系间相互跳转,为业务方提供更好的观测能力,包括实例、CPU、内存以及其他应用自定义的指标观测。
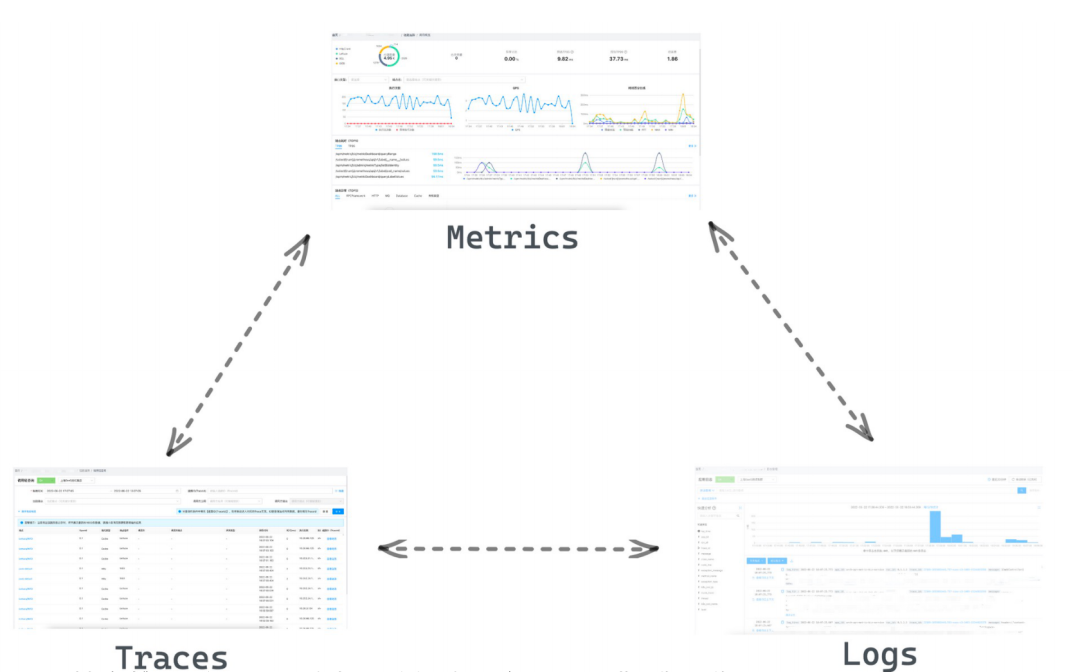
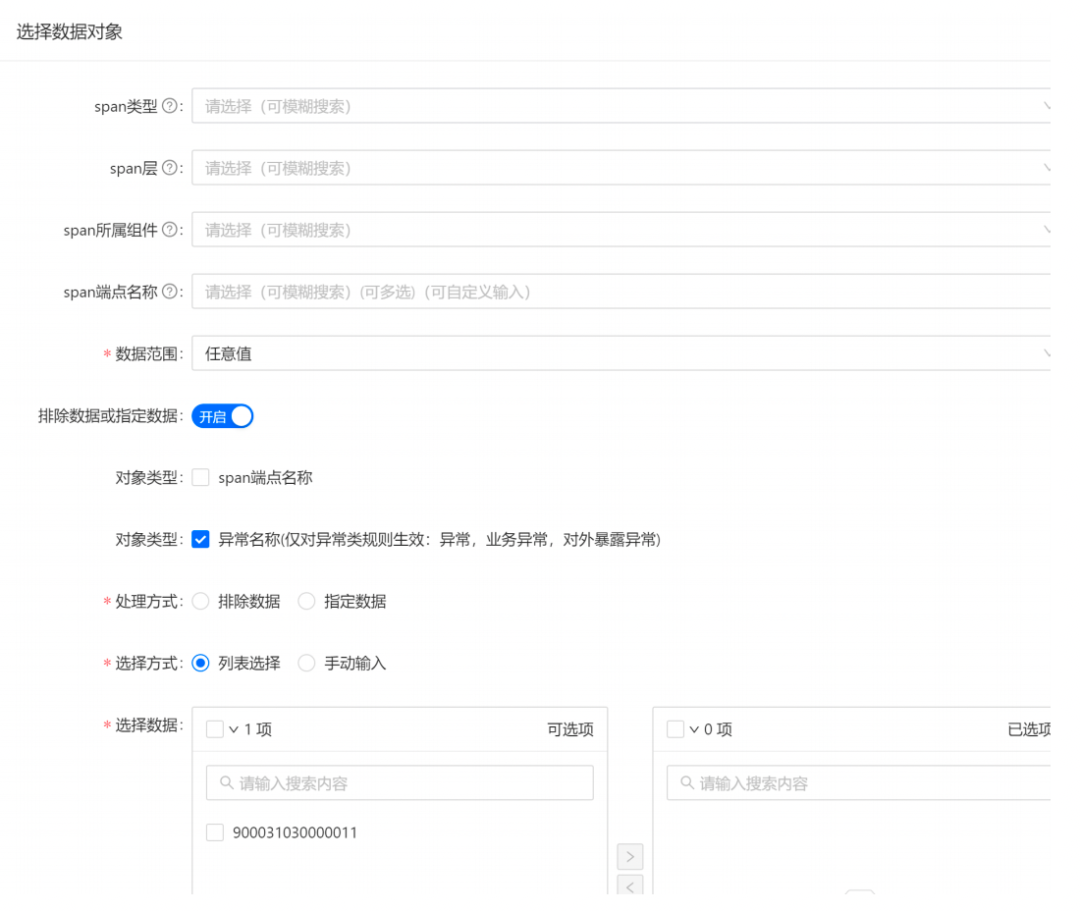
3.5.2 告警能力
一体化平台的告警能力支持按Span类型、层次、所属组件、端点名称等进行数据指定或排除。
3.6 一个降本增效的案例
1)问题描述
微盟此前数据存储了 6000 多亿条,但是线上调用链服务查询可能只有几千次,其中有非常大的资源浪费,在满足业务方查询诉求的基础上,存储成本需要做持续优化。

2)解决过程
- 采集异常链路信息,丢弃正常数据
我们通过链路染色采样来实现,其具体实现过程如下。
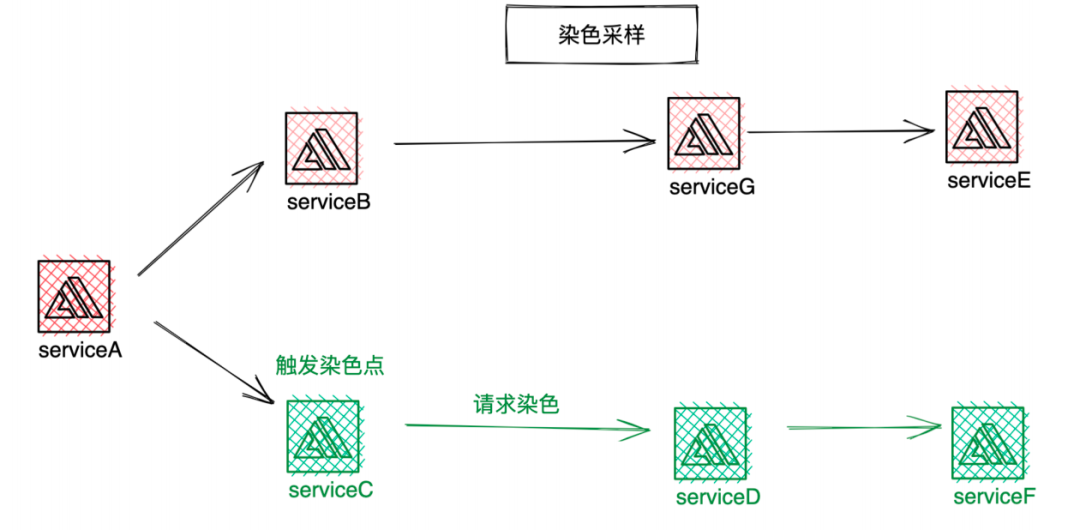
链路采样中,系统发现需要保存的链路就会触发染色,染色后的链路都会保存。染色的场景包括耗时染色采样、异常染色采样,比如某些耗时较高的链路则会染色保留。其他正常的链路会执行采样流程,命中采样规则后,Span会丢弃,微盟采样有组件比例采样和白名单模式两种规则。
DB请求和Cache请求均仅保留10%
在实践中我们发现链路有50%以上是 Redis 请求和DB请求,正常情况下调用链观测的是应用和应用之间的调用,对于业务方不太关注和价值度不高的链路,微盟目前线上保留比例是10%,以节省整体存储成本。
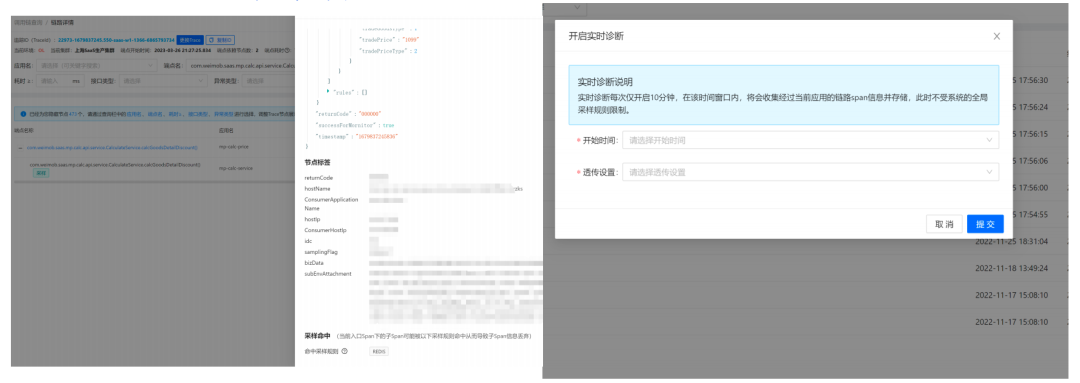
(链路采样&实时诊断页面)
若业务方希望在上线后观测应用情况,可以开启实时诊断,开启实时诊断后的10分钟内,链路信息可以做全保留,在此期间不涉及采样规则的限制。
3)实践效果
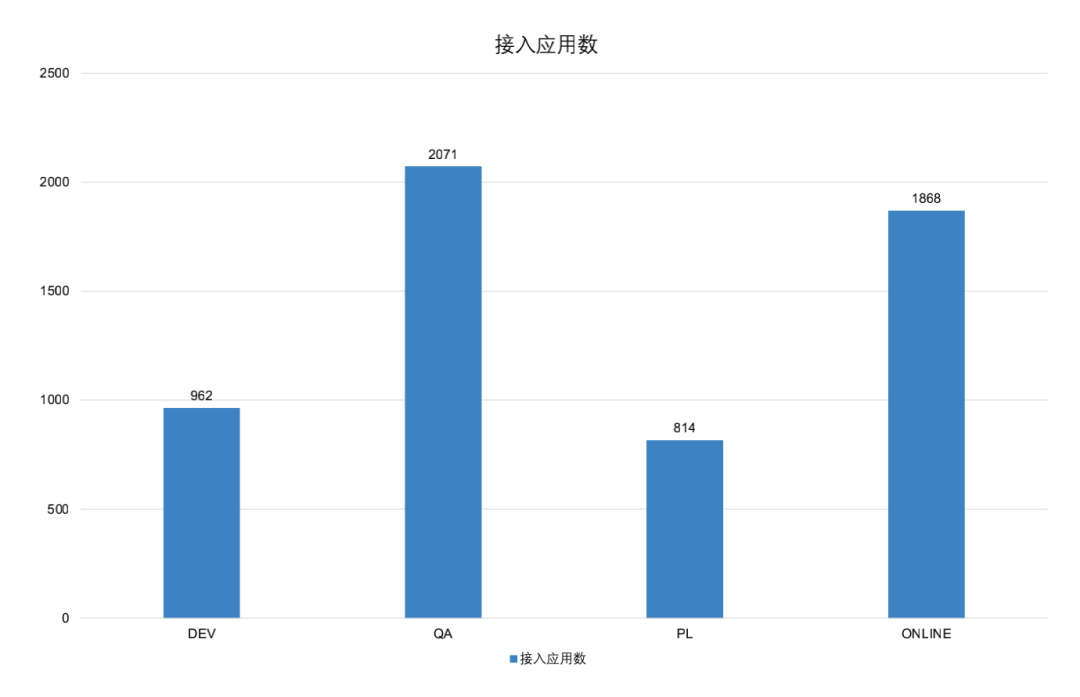
成本降低40%。线上推广链路采样后,DB和Cache的流量下降非常明显,链路的存储规模降低了40%左右,整体存储成本也降低了40%。

基本覆盖Online及QA环境中核心关键业务。
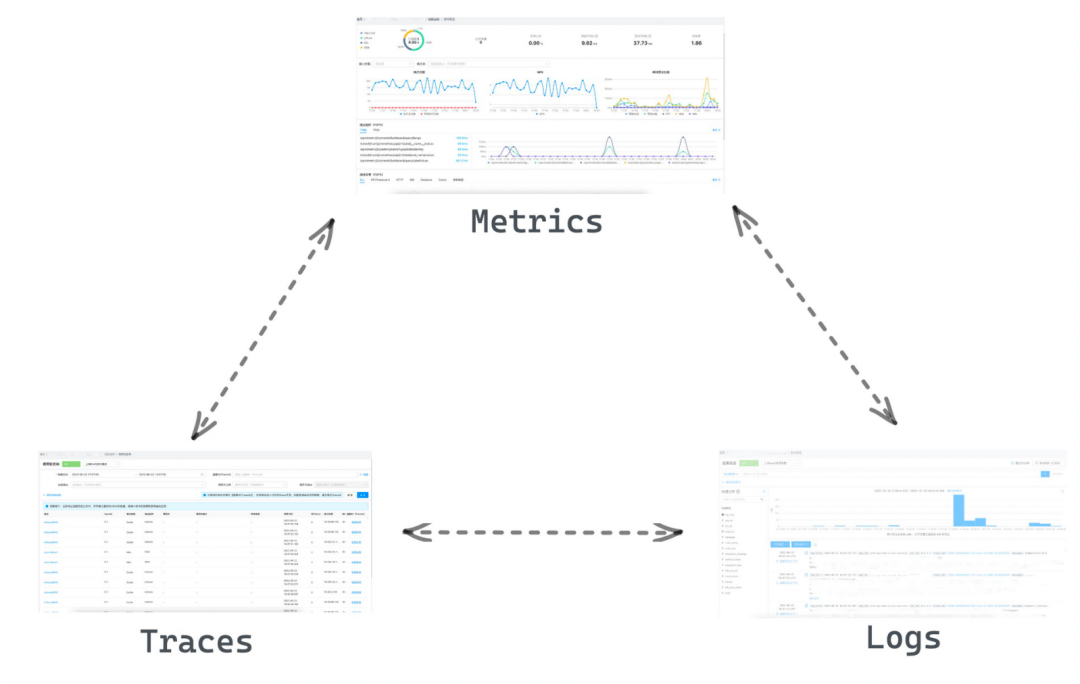
研发排障效率大幅提升。通过体系化的一站式APM平台大幅度提升了用户体验,同时减少了用户的排障成本。举个例子,业务方接到订单接口告警后,到链路指标排查订单接口指标,发现需要进一步排查,点击进入链路查询板块,直接定位异常链路,查看链路详情,假如需要进一步排障,点击查看日志,进入日志板块查看具体的链路信息,整个排障流程,清晰明了。而在此之前,同样的场景,排障流程繁琐,用户需要在多个平台检索,用户同样接收到订单接口告警后,需要到链路平台根据时间段检索链路ID,或者从响应体中抓取链路ID,假如没有及时抓到,那只能根据时间段进行检索了,抓到链路后,再到ELK中根据时间检索对应日志。
四、未来规划
在链路体系和指标体系的基础上,接下来我们会健全流量漏斗和告警溯源相关能力。
在大促场景下,通过流量拓扑图,为业务方提供入口到后端应用的流量放大比例,让业务方直观看到流量可能会对哪些应用产生影响。当某个应用出现问题后,业务方能快速进行应用级别的定位。
目前我们正在做相关的调研和探索,也欢迎有经验的朋友做交流。(全文完)
Q&A
1、技术实现上微盟还踩了哪些典型的坑?如何避坑?
2、Agent发布节奏如何把握?是否可以支持在运行时带上?
3、异步消息场景,上下游调用链如何串联?
4、整个调用链平台有开源计划吗?外部租户是否可以接入?
5、几千亿的数据有没有其他的数据价值,怎么利用?
更多详细内容:https://news.shulie.io/?p=6157,
观看完整版解答!


添加助理小姐姐,凭截图免费领取以上所有资料
并免费加入「TakinTalks读者交流群」

声明:本文由公众号「TakinTalks稳定性社区」联合社区专家共同原创撰写,如需转载,请后台回复“转载”获得授权。
本文由博客一文多发平台 OpenWrite 发布!