NNLM初认识以及相关代码
NNLM初学习
NNLM
在了解NNLM之前先了解一下词向量
词向量
我们人学过单词,汉字等等,能明白一句话。但是计算机只认识0和1,如何把语言让计算机看懂。将文本转化为向量。
词向量的方法是「one-hot(独热编码)表示法」
是最早的表示词向量的方法, 首先我们有一个词表,里面包括了我们可能会用到的所有词,每个词占据一个位置。那么词向量就是一个该词表维度大小的向量,词所在位置取值1,其它位置取值0。例如我们的词表有下面9个词:
你,我,他,是,谁,哪,里,来,自
“我”表示为向量[0, 1, 0, 0, 0, 0, 0, 0, 0],“是”表示为[0, 0, 0, 1, 0, 0, 0, 0, 0]
这样会可能会产生【维度灾难】和【语义鸿沟】
【维度灾难】:是因为如果词表过大,向量维度也过大,而且向量特别稀疏
【语义鸿沟】:因为每一个词向量1的位置不同,可以认为彼此相互正交(内积为0),任何两个内积为0,没有任何差别,体现不出来相似性。
为了弥补one-hot向量的这些缺陷,分布式向量(distributed representation) ,相似的词向量相似。这个与word enbedding关系, Representation → Distributed Reprensentation → word embedding ,词在基于神经网络的分布表示,好像同一个意思。
参考链接 (7 封私信 / 80 条消息) word2vec和word embedding有什么区别? - 知乎 (zhihu.com)
NNLM
Yoshua Bengio等人于2003年发表的《A Neural Probabilistic Language Model》针对N-gram模型的问题进行了解决。这是第一篇提出神经网络语言模型的论文,它在得到语言模型的同时也产生了副产品词向量。
论文链接:《A Neural Probabilistic Language Model》
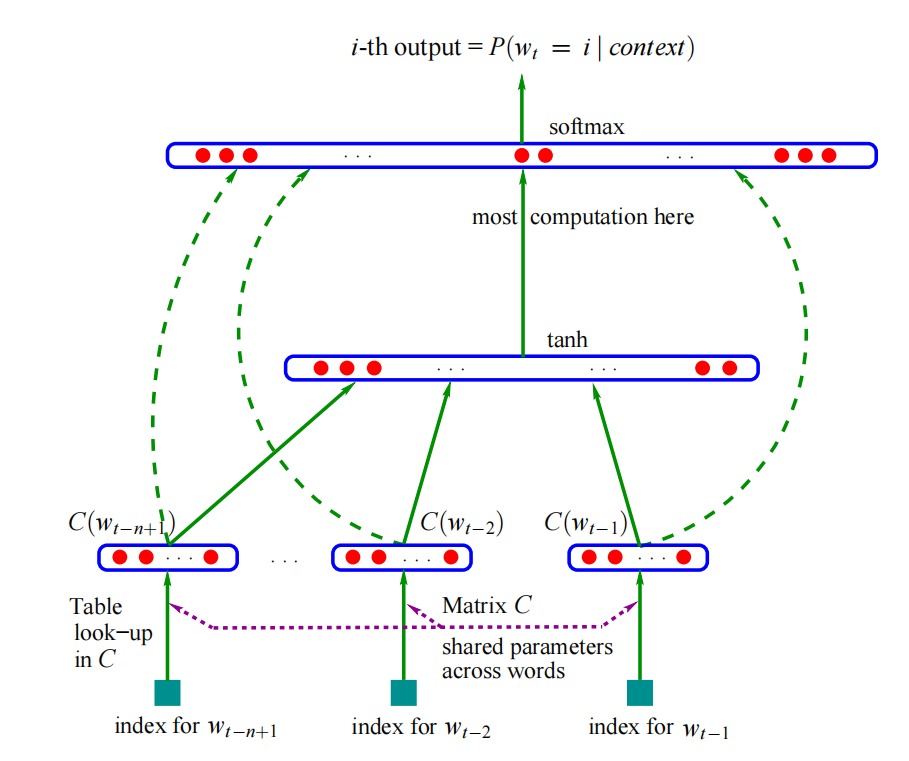
输入层:
通过前n个词,来预测第n个单词
词向量W:是一个one-hot向量,大小=[10W,1],W(t)表示第t个词语的one hot(一个元素为1,其余全为0
投影矩阵C:维度[D*V],V=10W,参数D根据文本大小不同来设定:谷歌测试时选取D=300。
计算过程:
- 投影矩阵C[300 * 10W] X 词向量W(t)[10W *1] 得到= 矩阵[300 * 1]
- 比如根据前3个词来预测第4个词语,那么上述操作会重复三次,得到3个[300*1]的矩阵
- 将这3个[300*1]的矩阵按行拼接,得到[900x1]的矩阵。
形式类似:
隐藏层:
存在一个向量矩阵[Hx1],H根据文本集合情况设定(谷歌测试时选取H=500)
该层完成的功能主要是全连接!
说通俗一些:把输入层计算得到的矩阵[900x1],转换为矩阵[Hx1],完成输入层到隐藏层的数据传输,并且在全连接的过程中存在计算的权重。
最终得到矩阵[500x1]
输出层:
我们的词语大小为V=10W,隐藏层计算得到矩阵[500x1],要将这[500x1]的计算结果转化为[10Wx1],以此来预测第4个词语是什么?
得到矩阵[10Wx1],也就是所谓第4个词ont-hot,最终经过SoftMax激活函数,选取行向量最大值,就是预测词语。
# code by Tae Hwan Jung @graykode
import torch
import torch.nn as nn
import torch.optim as optim
def make_batch():
input_batch = []
target_batch = []
for sen in sentences:
word = sen.split() # space tokenizer
input = [word_dict[n] for n in word[:-1]] # create (1~n-1) as input
target = word_dict[word[-1]] # create (n) as target, We usually call this 'casual language model'
input_batch.append(input)
target_batch.append(target)
return input_batch, target_batch
# Model
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__()
self.C = nn.Embedding(n_class, m)
self.H = nn.Linear(n_step * m, n_hidden, bias=False)
self.d = nn.Parameter(torch.ones(n_hidden))
self.U = nn.Linear(n_hidden, n_class, bias=False)
self.W = nn.Linear(n_step * m, n_class, bias=False)
self.b = nn.Parameter(torch.ones(n_class))
def forward(self, X):
X = self.C(X) # X : [batch_size, n_step, m]
X = X.view(-1, n_step * m) # resize [batch_size, n_step * m]
tanh = torch.tanh(self.d + self.H(X)) # [batch_size, n_hidden]
output = self.b + self.W(X) + self.U(tanh) # [batch_size, n_class]
return output
if __name__ == '__main__':
n_step = 2 # number of steps, n-1 in paper,
n_hidden = 2 # number of hidden size, h in paper
m = 2 # embedding size, m in paper
sentences = ["i like dog", "i love coffee", "i hate milk"]
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
number_dict = {i: w for i, w in enumerate(word_list)}
n_class = len(word_dict) # number of Vocabulary
model = NNLM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
input_batch, target_batch = make_batch()
input_batch = torch.LongTensor(input_batch)
target_batch = torch.LongTensor(target_batch)
# Training
for epoch in range(5000):
optimizer.zero_grad()
output = model(input_batch)
# output : [batch_size, n_class], target_batch : [batch_size]
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
# Predict
predict = model(input_batch).data.max(1, keepdim=True)[1]
# Test
print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
nn.Embedding( num_embeddings , embedding_dim )详解:
num_embeddings - 词嵌入字典大小,即一个字典里要有多少个词
embedding_dim - 每个词嵌入向量的大小。
input_batch[3:2 ]------>C(X)------->[3,2,2],input_batch每个不相同数都有一个2维向量,相同数的向量相同。
nn.Linear(in_features,out_features,bias=False)详解:
in_features指的是输入的二维张量的大小,即输入的[batch_size, size]中的size。
out_features指的是输出的二维张量的大小,即输出的二维张量的形状为[batch_size,output_size],当然,它也代表了该全连接层的神经元个数。
从输入输出的张量的shape角度来理解,相当于一个输入为[batch_size, in_features]的张量变换成了[batch_size, out_features]的输出张量。
input = [1 , 100]
nn.Linear(in_features = 100, out_features = 1)
output = [1,1]
参考链接: