大模型高效开发的秘密武器:大模型低参微调套件MindSpore PET
摘要:本文介绍大模型低参微调套件——MindSpore PET。
本文分享自华为云社区《大模型高效开发的秘密武器——大模型低参微调套件MindSpore PET篇》,作者:yd_280874276 。
人工智能进入“大模型时代”。大模型具备更强泛化能力,在各垂直领域落地时,只需要进行参数微调,就可以适配多个场景。因此,发展大模型已成为产学研各界共识。
在大模型开发方面,昇腾推出了大模型开发使能平台,基于昇思MindSpore构建了支撑大模型开发的全流程大模型使能套件,包括TransFormers大模型套件MindSpore TransFormers、以文生图大模型套件MindSpore Diffusion、人类反馈强化学习套件MindSpore RLHF、大模型低参微调套件MindSpore PET,支撑大模型从预训练、微调、压缩、推理及服务化部署。
本期,我们将开启“大模型高效开发的秘密武器”系列之首篇,为大家介绍大模型低参微调套件——MindSpore PET。
一、MindSpore PET介绍
MindSpore PET(MindSpore Parameter-Efficient Tuning)是基于昇思MindSpore AI融合框架开发的大模型低参微调套件。当前该套件提供6种算法,包含5种经典的低参微调算法LoRA、Prefix-Tuning、Adapter、LowRankAdapter、BitFit,以及1种用于下游任务精度提升的微调算法R_Drop。低参微调算法只需微调极少量的参数,即可在保持全参微调精度的情况下,大大节约计算和存储内存,减少微调训练的时间;精度提升的微调算法在几乎不增加计算内存及时间情况下,增加模型随机性,防止模型过拟合从而提高模型的正确率。
套件为所有算法提供了API调用接口及使用案例,实现开箱即用,并为低参微调算法提供了只保存极少的可学习参数的接口,使得生成的ckpt文件非常小。
开源仓地址:https://github.com/mindspore-lab/MindPet

二、MindSpore PET - LoRA
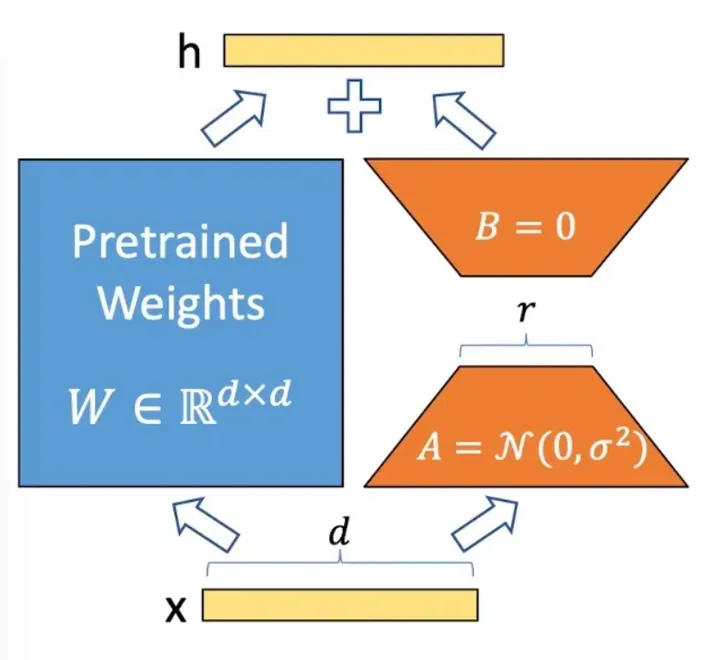
2.1 算法原理
LoRA: Low-Rank Adaptation of Large Language Models,是微软提出的一种针对大语言模型的低参微调算法。LoRA假设在适配下游任务时,大模型的全连接层存在一个低内在秩(low intrinsic rank),即包含大量冗余信息。因此提出将可训练的秩分解矩阵注入Transformer架构的全连接层,并冻结原始预训练模型的权重,从而可大大减少参与训练的参数量。
2.2 应用效果——以悟空画画为例
悟空画画模型是基于扩散模型的中文文生图大模型。虽然有强大的能力,但模型网络规模巨大,约9亿参数量,适配下游任务时训练时间长,计算和存储内存开销大。
经分析,悟空画画中使用CLIP模型将人类语言转换成机器能理解的数学向量,并通过 U-Net 模型预测噪声。这两种模型的Attention结构都包含全连接层,适配下游任务时可能含有大量冗余信息。
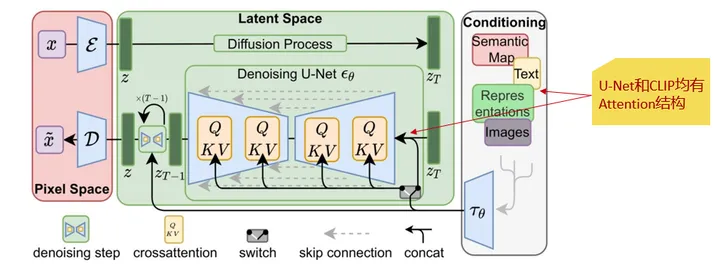
因此,我们分别在 U-Net的交叉注意力层q、k、v、output四个模块上,注入了LoRA模块,发现效果异常好。
如下图所示,适配LoRA后即使仅训练0.07%参数,也可以生成高质量的图像!

同时,相比全参微调,应用LoRA算法,训练性能也得到大幅提升:

- 原本端到端全参微调需17小时,适配后仅需9小时,节约近50%时间;
- 计算内存节约40%,可继续增大一倍batch_size,速度更快;
- 最终保存的ckpt大小才3.06MB,不再需要用4个GB保存所有参数。
这说明当有n个下游任务时,仅需保存n x 3.06MB,避免了n x 4GB的“庞然大物”。而且,我们还做了令人振奋的实验。如果用户训练了多种风格的模型,只需0.5s就可以切换风格,真正的无缝切换“毕加索”和“新海诚”!
原因在于MindSpore框架的静态图特性,只需要在第一次正向训练时编图,后续即使加载其它LoRA-ckpt更新参数,也无需重新编图。
2.3 使用方式
为大模型减轻负担的LoRA算法本身用起来也很轻松,端到端仅需简单五步就可以完成适配。
第一步:
将模型CrossAttention结构中qkvo的Dense层替换成LoRADense:
from tk.delta import LoRADense # original Dense Layer # self.to_q = nn.Dense(query_dim, inner_dim, has_bias=False).to_float(dtype) # replace Dense Layer with LoRADense self.to_q = LoRADense(query_dim, inner_dim, has_bias=False, lora_rank=4, lora_alpha=4).to_float(dtype)
第二步:
在训练脚本中调用冻结方法,仅训练新增的lora模块:
from tk.graph import freeze_delta # freeze all cells except LoRA and head freeze_delta(LatentDiffusionWithLoss, 'lora’)
第三步:
在训练脚本中将保存ckpt的ModelCheckpoint替换为TrainableParamsCheckPoint,仅保存需要更新的参数:
from tk.graph import TrainableParamsCheckPoint # original callback # ckpt_callback = ModelCheckpoint(...) # replace ModelCheckpoint with TrainableParamsCheckPoint ckpt_callback = TrainableParamsCheckPoint(...)
第四步:
根据训练目标调整学习率、batch_size等参数:
epochs: 15 start_learning_rate: 1e-4 end_learning_rate: 1e-6 train_batch_size: 3 warmup_steps: 0 lora_rank: 4 lora_alpha: 4
第五步:
训练完成后,在评估脚本中分别加载预训练ckpt和微调后生成的ckpt:
# 加载预训练ckpt pre_trained_pramas = load_checkpoint(pre_trained_ckpt_path) load_param_into_net(net, pre_trained_pramas) # 加载微调后生成的ckpt trainable_pramas = load_checkpoint(trainable_ckpt_path) load_param_into_net(net, trainable_pramas) # 开始评估 model.eval()
我们已经开源所有代码,并给出了详细的接口和用例介绍:
https://github.com/mindspore-lab/MindPet/blob/master/doc/TK_DeltaAlgorithm_README.md
需要注意的是相比全参微调,适配LoRA后一般要设置更大的学习率。如适配悟空画画时,我们就将学习率从1e-5增大到1e-4。
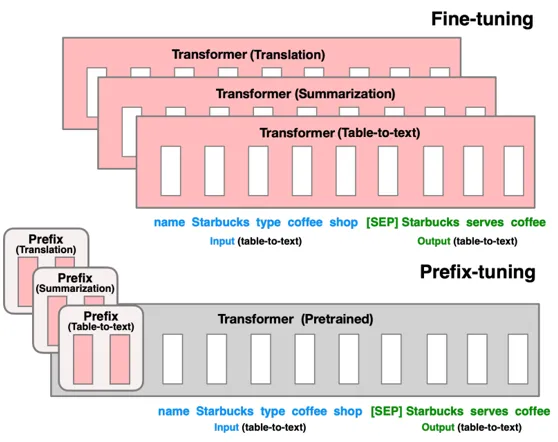
三、MindSpore PET - Prefix-Tuning
Prefix-Tuning: Optimizing Continuous Prompts for Generation,也是一种针对大语言模型的低参微调算法。研究人员提出,使用连续的向量而不是离散的词汇来构建前缀模板,即在输入前加入连续的token embedding,可以增加query和key的相关性。因此,Prefix-Tuning通过在每个multi-head attention的 key 矩阵和 value 矩阵前注入可训练的prefix向量k,v,并冻结原始网络参数,来大幅提升生成类任务的性能。
Prefix-Tuning在GPT-2和盘古Alpha大模型上都有很好的效果。与全参微调相比,在保持原有精度的前提下,使用Prefix-Tuning训练盘古Alpha仅需5.5%的参数量,节约了65%以上的计算内存,并将一个迭代的耗时缩短到一半。
四、MindSpore PET - Rdrop
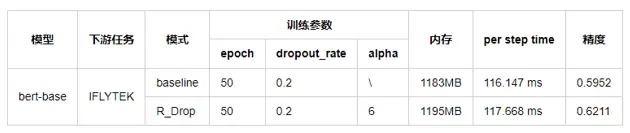
R-Drop: Regularized Dropout for Neural Networks,是一种用于提升精度的微调算法,主要通过简单的“两次Dropout”来构造正样本进行对比学习,增加模型随机性。具体是在模型加载完一个batch的数据集之后,复制一份该数据,并同时输入到模型中,然后分别计算损失函数,并将结果相加得到最终的loss值。尽管逻辑非常简单,却能很好的防止模型过拟合,进一步提高模型的正确率。经在Bert上多个下游任务上验证,几乎保持同样的内存和时间开销,就能提升2.6个点的精度。
大模型开发到部署是一个高门槛、复杂的过程,大模型使能套件将帮助开发者,让大模型更易开发、易适配、易部署。
想了解更多关于TransFormers大模型套件MindSpore TransFormers、以文生图大模型套件MindSpore Diffusion、人类反馈强化学习套件MindSpore RLHF的相关信息,请关注昇思MindSpore公众号,我们将持续为大家带来人工智能领域技术干货和活动消息。