【pandas基础】--数据检索
pandas的数据检索功能是其最基础也是最重要的功能之一。
pandas中最常用的几种数据过滤方式如下:
- 行列过滤:选取指定的行或者列
- 条件过滤:对列的数据设置过滤条件
- 函数过滤:通过函数设置更加复杂的过滤条件
本篇所有示例所使用的测试数据如下:
import pandas as pd
import numpy as np
fp = "http://databook.top:8888/pandas/cn-people.csv"
df = pd.read_csv(fp)
df

1. 行列过滤
pandas中最常用的按行或者按列选择数据的函数是 loc 和 iloc。
1.1 loc 函数
loc函数通过标签索引选择行列数据,可以在一个语句中同时指定行和列的条件。
按范围选取行:
df.loc([1:5, :])

选取指定的行:
df.loc[[1, 5], :]

按范围选取列:
df.loc[:, "年份":"指标中文"]

选取指定的列:
df.loc[:, ["年份","指标中文"]]

行和列也可以同时设置:
df.loc[1:3, ["年份","指标中文"]]

1.2 iloc 函数
iloc函数通过整数位置索引选择行列数据。
这种方法与loc方法类似,但是它使用整数位置而不是标签。
按范围选择行:
df.iloc([1:5, :])

注意这里可以看出iloc和loc的区别,同样的范围[1:5],
iloc不包括index=5的数据,而loc是包括index=5的数据。
选择指定的行:
df.iloc[[1, 5], :]

这种选择方式下,iloc和loc函数返回的结果是一样的。
按范围选择列:
df.iloc[:, 0:3]

注意,这里是 iloc和loc的另一个区别,
iloc只能用数字序列来表示列的范围(第一列对应数字0),
回顾之前的loc函数,我们可以用列名来表示范围的df.loc[:, "年份":"指标中文"]。
另外,iloc表示列的范围0:3表示是0,1,2三列,不包括3这一列。
选择指定的列:
df.iloc[:, [0, 2]]

同loc一样,iloc也可以行和列同时设置:
df.iloc[1:5, [0, 2]]

2. 条件过滤
行列过滤的方式是基于索引和列名称来过滤的,除此之外,还可以根据列的值来过滤。
这也是分析时常用的过滤方式。
2.1 单条件
根据列的值来过滤,列的值是数值还是字符串都可以。
df[df["年份"] > 2020]

字符串的过滤方式:
df[df["指标中文"].str.contains("乡村")].head()

2.2 多条件
除了设置单独的条件之外,也支持通过逻辑符号&和|来设置多个条件。
df[(df["年份"] > 2020) & (df["指标中文"].str.contains("乡村"))]
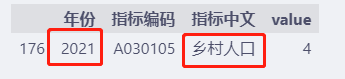
必须同时满足年份>2021和指标中文包含乡村两个条件的数据,只有1条。
df[(df["年份"] > 2020) | (df["指标中文"].str.contains("乡村"))].head(6)

只要满足年份>2021和指标中文包含乡村两个条件之一的数据。
3. 函数过滤
pandas中还有两种通过函数来过滤和转换数据的方式,这种方式可以将自定义的函数应用到数据之上。
这样就提供了相当灵活的数据操作方式。
3.1 apply
针对DataFrame某一列数据的apply。
比如下面的示例增加一列,其值是将value列的数据放大10倍:
df["value10倍"] = df["value"].apply(lambda x: x*10)
df

3.2 map
针对DataFrame某一列数据的map。
比如下面的示例增加一列,其值是设置指标中文的缩写。
df["指标缩写"] = df["指标中文"].map({"年末总人口": "总人口", "乡村人口": "乡村"})
df

4. 总结回顾
本篇主要介绍了pandas数据检索的常用方式,数据检索是做分析时最常用的步骤。
通过数据过滤方法,快速确定用于分析的数据范围,剥离无用的数据,提高分析的效率。
数据检索方式由易到难分别为:
- 行列过滤,
loc和iloc - 条件过滤,单条件和多条件过滤
- 函数过滤,自定义函数灵活的调整已有列的数据
本文关联的微信视频号短视频:

热门相关:最强狂兵 名门天后:重生国民千金 夫人,你马甲又掉了! 战神 横行霸道